I. Introducción
La presentación de los escritos de demanda y contestación cumpliendo con los requisitos exigidos en el Anexo IV.5.6 RD 1065/2015 de 27 de noviembre (LA LEY 18232/2015), entre ellos el reconocimiento óptico de caracteres (en adelante OCR), tiene mayor importancia de la que muchos podrían creer, y el futuro que nos plantea puede estar repleto de sorpresas.
Los discursos en torno a la digitalización y modernización de la justicia se centran siempre en la eliminación del papel, sin embargo, la importancia no radica en que prescindamos del papel para trabajar, sino en que la información que en tales papeles figuraba, ahora está digitalizada y es «tratable». Y es esta posibilidad de tratar el texto de los escritos, la que ofrece el mayor potencial para la agilización de la Justicia y para la automatización de buena parte de la labor judicial.
Los escritos con OCR nos ofrecen la posibilidad de que a través de algoritmos podamos extraer información de interés para la gestión de los Sistemas de Gestión Procesal. Actualmente, los sistemas como Atlante, Adriano, Minerva o Avantius, se nutren de los datos que los funcionarios introducen manualmente, a saber, las partes, los profesionales, los DNIs, los CIF, las direcciones etc… Esta forma de proceder recuerda a la dinámica que seguían los originales buscadores de internet, como Yahoo o Altavista. Dichos buscadores indexaban páginas en sus bases de datos, a petición del propio webmaster o por la labor de búsqueda y clasificación de sus trabajadores. Los trabajadores de Yahoo, clasificaban las páginas manualmente según su temática. Posteriormente llegó Google, que sustituyó la labor de esos trabajadores por un algoritmo que rastreaba internet e iba clasificando de manera autónoma las webs. Estos algoritmos se popularizaron posteriormente, y se conocen como Web Crawlers.
En el momento actual, los sistemas de Gestión Procesal se encuentran en la misma tesitura que los buscadores de Internet en 1998, sin embargo, el desarrollo de LexNet, los escritos en OCR y algoritmos con IA, permitirán que podamos equipararnos a los buscadores de Internet del año 2000.
Sin embargo, la posibilidad de tratar el texto de una demanda o de una contestación, no solo puede beneficiar a los Sistemas de Gestión Procesal, y por ende, automatizar la labor que actualmente se desarrolla manualmente por los funcionarios, sino también puede facilitar el trabajo de los Jueces y Magistrados. Para ello, a través de un simple ejemplo, podrá mostrarse cómo una demanda bien presentada, permite obtener una información valiosa que ahorre tiempo a la hora de resolver.
II. Un caso de uso
En el ámbito de la jurisdicción social, no hay contestación por escrito, por lo que los Juzgadores, a la hora de enfrentarse a una vista sólo cuentan con la demanda. Sin embargo, de este escrito se pueden obtener datos importantes a la hora de preparar el Juicio, más aún, si contamos con modelos para cada tipo de procedimiento.
El procedimiento más habitual en la jurisdicción social son los despidos, y en estos pleitos los datos a la hora de preparar el borrador de resolución son los nombres de las partes, el salario, las fechas de antigüedad y despido y la indemnización que en su caso pudiera proceder. Para poder preparar este borrador, habremos de transcribir cada uno de esos datos en los lugares pertinentes de los modelos. Para ello podremos, bien escribir los datos, o bien copiarlos del «.pdf» de la demanda. En ambos casos perdemos tiempo, en el primero hay que buscar los datos y escribirlos, en el segundo hay que buscarlos, copiarlos, acudir al procesador de textos y pegarlos. Sin embargo, el hecho de que estos datos se encuentren digitalizados nos facilita la labor de automatizar la preparación de modelos, de tal manera que sólo deberíamos tener los «.pdf» en la carpeta de «Documentos» para que un algoritmo hiciera el resto.
En el caso de mi partido judicial, estudié cuáles eran los Despachos de Abogados que acumulaban un mayor porcentaje de demandas de despidos. Después de un tiempo en cualquier Juzgado es usual conocer que dos o tres Despachos acumulan más del 50% de las demandas en alguna materia. Una vez concretados estos Despachos, tres, analicé la estructura de cada una de sus demandas, y cómo se estructuraban los datos de interés en dichos escritos. Cada Despacho suele tener sus propios modelos de Demanda, por lo que analizar las estructura de los más prolíficos y sacar patrones, nos ayudará a ahorrar tiempo a la hora de preparar los pleitos y automatizar el trabajo repetitivo y carente de valor añadido.
Una vez elegidos los Despachos que acumulaban el 70% de las demandas de despido, y estudiada la estructura de los modelos de sus escritos, hay que pasar a hacer el preprocesamiento del texto.
El lenguaje elegido para crear un algoritmo con el que automatizar la obtención de datos de interés fue Python, un lenguaje de programación generalista, de fácil comprensión y aprendizaje, con buenas librerías para hacer tratamiento de lenguaje natural.
III. Indemnización por despido
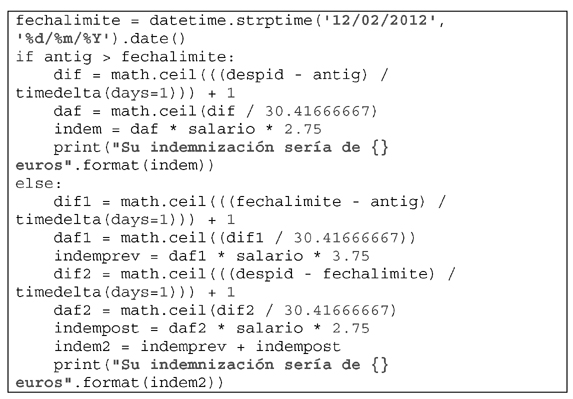
Las consecuencias jurídicas del despido improcedente vienen contempladas en el artículo 56.1 del Estatuto de los Trabajadores (LA LEY 16117/2015). En el mismo, se prevé que el empresario, en el plazo de cinco días desde la notificación de la sentencia, puede optar entre la readmisión del actor con abono de los salarios de tramitación, y el pago de la indemnización prevista en el artículo 56.1.a) del Estatuto de los Trabajadores; esto es, una indemnización igual al importe de treinta y tres días de salario por años trabajado con prorrateo de los periodos inferiores al años y con un máximo de cuarenta y dos mensualidades, a lo que deberá añadirse también el importe de los salarios de tramitación en la forma prevista en el artículo 56.1.b) del Estatuto de los Trabajadores.
Así mismo, para el caso de despidos en los que la antigüedad del trabajador sea previa al 12 de Febrero de 2012, habremos de acudir a la Disposición Transitoria Quinta del Real Decreto-ley 3/2012, de 10 de febrero, de medidas urgentes para la reforma del mercado laboral (LA LEY 1904/2012), cuya apartado segundo dispone:
«La indemnización por despido improcedente de los contratos formalizados con anterioridad al 12 de febrero de 2012 se calculará a razón de cuarenta y cinco días de salario por año de servicio por el tiempo de prestación de servicios anterior a dicha fecha, prorrateándose por meses los periodos de tiempo inferiores a un año, y a razón de treinta y tres días de salario por año de servicio por el tiempo de prestación de servicios posterior, prorrateándose igualmente por meses los periodos de tiempo inferiores a un año. El importe indemnizatorio resultante no podrá ser superior a setecientos veinte días de salario, salvo que del cálculo de la indemnización por el periodo anterior al 12 de febrero de 2012 resultase un número de días superior, en cuyo caso se aplicará este como importe indemnizatorio máximo, sin que dicho importe pueda ser superior a cuarenta y dos mensualidades, en ningún caso.»
De la lectura de dichos artículos lo que se aprecia es que la información a obtener de la demanda es en definitiva la fecha de antigüedad y despido, y el salario.
Del examen del artículo 56.1 del Estatuto de los Trabajadores (LA LEY 16117/2015), tenemos por tanto que la decisión sobre la indemnización sigue unas instrucciones precisas que son perfectamente codificables en un algoritmo.
El paso para automatizar esa operación será la de que un algoritmo extraiga los datos necesarios de la demanda, haga la operación aritmética y nos ofrezca el resultado.
IV. Aplicación práctica
Lo primero para crear un programa de extracción de datos de una demanda, será importar las librerías oportunas:
import pdftotext from nltk.tokenize import word_tokenize from datetime import datetime, timedelta import re from nltk.corpus import stopwords import math import nltk |
La primera librería para importar es «pdftotext», esta librería permite extraer del «.pdf» de la demanda el texto de la misma.
La segunda librería es «nltk», una librería muy importante para el tratamiento del Lenguaje Natural, con una gran cantidad de funciones para obtener datos interesantes y que en este caso nos servirá para tokenizar el texto de la demanda, esto es, dividir el texto en palabras (word_tokenize). Hay otras librerías de tratamiento de lenguaje naturales como «spacy», pero en este ejemplo simple, usaremos «nltk».
La tercera librería es «datetime», que nos permitirá convertir la fecha de antigüedad y de despido en datos tratables para poder calcular la indemnización.
La cuarta librería es «re», que nos permitirá utilizar Expresiones Regulares para poder buscar palabras por patrones.
La quinta librería es «math», que nos permitirá realizar operaciones matemáticas para calcular la indemnización por despido.
Lo primero que haremos será extraer el texto del «.pdf» de la demanda y asignar el texto a un variable que denominaremos «document». En consecuencia, tendremos toda la demanda, en la variable «document» como una sola cadena.

Una vez que tenemos el texto de la demanda, tendremos que pasar a preprocesarlo para poder tratar el mismo, eliminando lo que se denomina «ruido». Para ello usaremos una expresión regular que eliminará caracteres especiales, obteniendo así un texto limpio (cleaned):

Una vez hemos limpiado el texto, pasaremos a tokenizar el mismo, es decir, pasar de que el texto sea una cadena, a ser una lista de valores. A título de ejemplo:

Cada palabra será un valor individual y la lista tendrá la longitud del número de palabras que tenga la demanda. Al tokenizar un texto, cada palabra tiene un índice en la lista, por lo que resulta más sencillo identificarla en el texto. Así, la primera palabra tendrá el identificador [0], la segunda palabra el índice [1] y así sucesivamente.
cadena = "Al Juzgado de lo Social que por turno corresponda" lista_de_valores = ['Al', 'Juzgado', 'de', 'lo', 'Social', 'que', 'por', 'turno', 'corresponda'] |
En el caso de la demanda real empleada para el presente ejemplo, como se aprecia, la frase se convierte en una lista de valores individuales (tokens) que denominamos con la variable «tokenized». Pasamos el texto «cleaned» por la función word_tokenize(), y además, añadimos a la variable «cleaned» la función «.lower()», para que todo el texto de la demanda esté en minúsculas, evitando así que cuando busquemos palabras concretas, no se encuentren por la capitalización de las mismas.
Así pues, la demanda ha pasado de ser un texto normal:


A ser una lista de variables:
Como se ha señalado, la primera palabra, «al» sería la palabra [0] y la palabra «social» sería la [4].
Una vez tokenizado el texto, pasaremos a eliminar las palabras denominadas «stopwords», esto es, palabras vacías que se ignoran a la hora de analizar los textos, como: a, al, aquel, de, el, es, tan, y, etc…

Igualmente, eliminaremos cada variable de la lista que sea sólo una «,» o un «.»:

El «textdef» o texto definitivo, será el texto con el que trataremos a la hora de obtener los datos de interés de la demanda. Este «textdef» se obtiene de eliminar de la lista «tokenized» las stopwords o palabras vacías.
Así, el texto resultante, es el siguiente:

Como se aprecia, hemos eliminado el ruido, las palabras vacías y tenemos el texto preprocesado para poder trabajar con el mismo. A partir de aquí, podemos extraer los datos de interés. Como se señaló, a la hora de preparar un borrador de Sentencia, necesitaríamos los nombres de las partes, fechas y cantidades. Esos son los datos que obtendremos.
Lo primero será crear dos variables con expresiones regulares que nos permitan identificar patrones de datos que nos interesan. En vez de buscar un salario concreto, lo que buscaremos será aquel valor que contenga dígitos, lo mismo cabe decir de la fecha. Dado que hemos procedido a un análisis previo de las demandas, veremos si unos Despachos emplean fechas numéricas o fechas alfanuméricas, para poder crear el patrón mediante expresiones regulares. En el caso del ejemplo, dos despachos coinciden en estructura de sus demandas, por lo que utilizaremos la misma expresión regular para identificar fechas y salarios.

Una vez creadas las variables de las expresiones regulares, comenzaremos a analizar el texto. El código es el siguiente:

Lo primero que haremos será un «loop» o bucle, por el cual, el programa analizará cada una de las palabras «word» del texto definitivo preprocesado «textdef». Así, cada vez que analice una palabra, hará distintas comprobaciones.
Para poder comprender este código, habrá que mostrar cómo se estructura la demanda elegida como ejemplo:

Como se aprecia, los huecos en blanco identifican al profesional y a las partes demandante y demanda, analizando el texto lo que se constate es que en este modelo de Sentencia (de un despacho que acumula un alto porcentaje de litigios), primero se pone el nombre del profesional y luego el de la parte actora, parte actora cuyo nombre estaría flanqueado entre las palabras «representación» y «mayor». La palabra «de» no flanquearía al nombre del actor, porque la palabra «de» es una stopword y se eliminó previamente. Igualmente, la coma «,» no flanquearía tampoco al nombre del actor, dado que al limpiar el texto (textprov) la habríamos eliminado también. Lo mismo cabría decir del nombre del demandado, que estaría entre la palabra «empresa» y la palabra «cif». La antigüedad estaría a continuación de la palabra «antigüedad».

El despido siempre estaría —conforme a la frase utilizada por el modelo de demanda de este despacho— tras la palabra «efectos», a saber, «los efectos del despido son de 31/10/2019», o también la frase empleada por otro despacho de «la efectividad del despido es 31/10/2019».
Dado que hemos eliminado las stopwords, el resultado será siempre «efectos» o «efectividad», «despido» y la fecha del despido.

Por tanto, examinando este modelo de demanda, podemos saber en qué lugar exacto se encuentra cada uno de los datos que nos interesa, de todas las demandas de despido de este Despacho. De hecho, del análisis de varios modelos de demandas, se aprecia que las fechas de antigüedad y de despido son siempre la primera que aparece en la demanda (la antigüedad aparece en el hecho primero y siempre en formato distinto al del resto de fechas) y la última que aparece en la demanda (la fecha del despido aparece en el Suplico al solicitar la improcedencia). Por lo que una forma más sencilla y limpia de obtener ambas fechas sería la de crear una lista con todas las fechas de la demanda, y atribuir a la variable «antig» la primera y la variable «despid» a la última:

Explicada ahora la ubicación de cada elemento, el código resulta más legible.
Para poder extraer la información, usaremos una sentencia «if», en virtud de la cual, si la palabra examinada (habíamos iniciado previamente un bucle que analizaba cada palabra de la lista) coincide con la palabra clave que nos interesa, haremos una acción consecuente.
A los valores de fechas, les pasaremos la función datetime.strptime para que tenga un valor de fecha y puedan posteriormente hacerse los cálculos para la indemnización por despido.
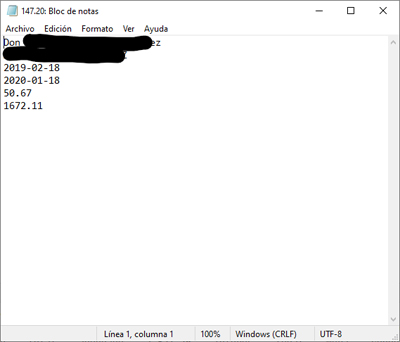
Una vez realizadas todas las comprobaciones de cada una de las palabras de la lista obtendremos los siguientes datos de interés:

Este texto se mostrará de la siguiente forma (se ocultan los datos de demandante y demandado):
La parte actora XXX XXXX XXX tiene una antigüedad de 2019-02-18 con un salario de 50.67 euros y fue despedida por la empresa XXX XXXX XXXX en fecha 2020-01-18. Su indemnización sería de 1672.11 euros |
Una vez que tenemos todos estos datos, podemos proceder al cálculo de la indemnización, para lo cual usaremos los datos que hemos extraído del texto, a saber, salario, antigüedad y fecha de despido:

Todos estos datos carecerían de interés si obraran en un terminal, por lo que deberemos crear un archivo con los datos de cada procedimiento. De tal manera que cada vez que pasemos el archivo «.pdf» de la demanda por el algoritmo, se cree un archivo de texto con los datos de interés y con el mismo nombre que el archivo «.pdf», para poder identificar los datos de cada procedimiento.

Este archivo, nos serviría para ahorrar tiempo a la hora de buscar los datos que de utilidad para preparar el borrador de Sentencia.
V. Uso de funciones en Python
Examinado lo que antecede, nos encontramos ante una sencilla implementación de soluciones en Python para la extracción de información de un documento, a saber, de una demanda en formato «.pdf» con «OCR».
Sin embargo, este código resulta demasiado específico, dedicado, resultando de mayor interés optar por una programación genérica que permita aplicar el algoritmo a un gran número de documentos de manera simultánea y desatendida. Para ello, podemos acudir a las «funciones». A saber, crear funciones que desempeñen una tarea concreta y específica, de tal manera que el archivo definitivo «.py» contendrá simplemente la invocación de aquella «funciones» que nos interesa. Así por ejemplo, podemos crear una función concreta para abrir un documento en pdf, extraer su texto y poder trabajar sobre el mismo:
import pdftotext def abrirpdf(pdf): with open(pdf, "rb") as f: archivo = pdftotext.PDF(f) document = "\n\n".join(archivo) return document |
De manera sucesiva, podemos convertir en funciones todas y cada una de las tareas que antes hemos expuesto, si bien dividiendo dichas tareas en suficientes pasos como para que más tarde podemos invocar dichas funciones en otras nuevas.
La tarea subsiguiente para que podamos trabajar sobre el texto extraído será la de limpiarlo y tokenizarlo, como se expuso ut supra, para ello, crearemos una función a la que sólo le ofreceremos como parámetro el texto extraído y nos devolverá el mismo limpio y tokenizado.
def preparar_texto(texto): from nltk.corpus import stopwords cleaned = re.sub(r'[^A-ZñÑa-zÁ-Úá-úä-ü0-9.€,\/]+', ' ', texto) tokenized = word_tokenize(cleaned.lower()) stopwords = set(stopwords.words('spanish')) textprov = [word for word in tokenized if word not in stopwords] t = list() for i in textprov: if re.match('\,', i): t.append(i) if re.match('\.', i): t.append(i) textdef = [word for word in textprov if word not in t] return textdef |
Una vez obtenido el texto y preparado, crearemos las funciones necesarias para obtener los datos necesarios.
1. Fecha del despido
Una vez abierto el documento, podemos crear una función genérica para buscar palabras, esta función nos permitirá encontrar una palabra en un texto, o avisarnos si dicha palabra no existe.
def buscador(texto, valor): matches = list() for index in range(len(texto)): if texto[index] == valor: matches.append(index) if matches: return matches else: raise ValueError("{} no está en {}".format(valor, texto)) |
Esta función no nos devolverá la palabra dentro del texto, sino el índice que dicha palabra ocupa en el texto, o mejor dicho, nos devolverá una cadena con los índices de las distintas veces que se repite la palabra que buscamos.
Sin embargo, a la hora de obtener los datos que nos interesan, por ejemplo la fecha del despido, nos resulta de mayor interés saber qué palabras rodean a la palabra que buscamos, dado que si el trozo de texto «02/04/2020» es una palabra cercana a la palabra «despido», será más probable que dicho trozo de texto sea la fecha del despido, a que sea la fecha de antigüedad. De ahí que creemos dos funciones, la de palabras cercanas y la de fechas cercanas a despido. La primera función, nos devolverá una cadena con el índice de las palabras que rodean a la buscada.
def palabras_cercanas(texto, palabra, *lista): for index in lista: if palabra in texto[(index-2):(index+2)]: return index |
La segunda función, examinará si las palabras o tokens cercanos a la palabra «despido» tiene formato de fecha y en caso de ser así, formateará la fecha para que sea tratable.
def fecha_cercana_despido(texto, palabras_cercanas): lista = texto[(palabras_cercanas-3):(palabras_cercanas+4)] fecha = [word for word in lista if re.match('\d{1,2}(\/|\.|\-)\d{1,2}(\/|\.|\-)\d{1,4}', word)] fechaclean = re.sub('\,|\.|\-|\/', '', fecha[0]) return datetime.strptime(fechaclean, '%d%m%Y').date() |
Como se aprecia, esta segunda función hace uso de la anterior. El uso de funciones sirve para dividir las tareas en pequeñas porciones de código, y así poder usar esa tarea concreta (buscar una palabra en el texto, formatear una fecha etc…) dentro de otra mayor sin repetir código. La finalidad es simplificar el código y hacerlo más legible.
Como se puede ver, en esta segunda función se hace uso, en la tercera línea de una «List Comprehension», en la cuarta se hace uso de la librería «re» y en la quinta de la librería «datetime». Para ello, previamente hemos tenido que importar dichas librerías. De tal manera que en el archivo en el que estamos creando las funciones, se importarán las librerías que usamos y en el archivo definitivo donde el código aplique estas funciones a una multitud de archivos, habremos de importar estas funciones creadas por nosotros. A saber, en el primer archivo importaremos todas las librerías necesarias:
import re from datetime import datetime from nltk.tokenize import word_tokenize import math import pdftotext |
Y en el archivo en el que hagamos unos tratamientos de las demandas por lotes, importaremos las funciones que hemos creado previamente.
| from Buscador import buscador, palabras_cercanas, fecha_cercana_despido, salario, indemnizacion_despido_completa, antiguedad, abrirpdf, preparar_texto |
Como se aprecia, al estar ambos archivos en la misma ubicación importaremos desde el archivo original «Buscador.py», las funciones que nos interesen.
Una vez que hemos creado las anteriores funciones, su aplicación sobre el texto concreto podría ser la siguiente:
def despido(texto): try: a = buscador(texto, 'efectos') except: b = buscador(texto, 'efectividad') try: c = palabras_cercanas(texto, 'despido', *a) except: d = palabras_cercanas(texto, 'despido', *b) try: e = fecha_cercana_despido(texto, c) return e except: f = fecha_cercana_despido(texto, d) return f |
La finalidad de esta función es arrojar la fecha de efectos del despido, para ello usamos la función «buscador», que busca dentro del texto la palabra «efectos» o la palabra «efectividad», en caso de que la anterior no esté. Usamos las formulas «try» y «except», cuya función es, si «try» no arroja un valor válido, prueba con «except», así evitamos que el código nos arroje un «ERROR».
En este caso, empleamos como palabra clave «efectos» y «efectividad», la función error nos arrojará una lista con los índices en los que aparece la palabra «efectos» o «efectividad» en el texto de la demanda. Normalmente en una demanda de despido se suelen usar las fórmulas «la fecha de efectos del despido es DD/MM/AAAA» o la de «La fecha de efectividad del despido es DD/MM/AAAA» o cualquier otra fórmula semejante, pero en todo caso, la palabra «efectos» y «efectividad» siempre circunda a la fecha del despido.
A continuación usamos la función «palabras_cercanas» que tiene por finalidad buscar si cerca de la palabra efectos se encuentra la palabra «despido». En ocasiones, en un texto pueden usarse las palabras «efecto» o «efectividad» sin referirse al despido sino a cualquier otra cuestión, por ello, depuraremos la palabra que nos interesa para saber, cuál de todos los índices del texto que tienen la palabra «efecto» o «efectividad», tienen cerca la palabra «despido», dado que ello nos asegurará que si a una distancia de pequeña aparecen las palabras «despido» y «efectos» o «efectividad», es porque se está refiriendo a la fecha del despido, dato que nos interesa.
Por último, hacemos uso de la función «fecha_cercana_despido», que buscará dentro de una cadena creada al efecto, con los 4 tokens que preceden a «despido» y los 4 tokens que suceden a dicha palabra, si alguno de esos es una fecha. Una vez encontrada, la limpiará (fechaclean = re.sub('\,|\.|\-|\/', '', fecha[0])) y convertirá en una fecha tratable con la librería «datetime».
En suma, con todas las funciones anteriormente creadas, usadas una sobre otra, podremos encontrar la fecha del despido, que nos servirá posteriormente para el cálculo de la indemnización por improcedente.
2. Fecha de antigüedad
Para obtener la fecha de antigüedad, podríamos acudir a las funciones anteriores, si bien algo modificadas. En toda demanda de despido la antigüedad suele ir precedida de esta misma palabra, por lo que con la función «buscador», buscaríamos los índices de la palabra «antigüedad» en el texto, y una vez hecho esto, podríamos buscar un token con formato fecha que suceda a la palabra «antigüedad».
Sin embargo, también podemos analizar los textos de las demandas para observar que la primera fecha que aparece en toda demanda de despido es la de antigüedad. Para ello, podríamos tomar todas las fechas del texto y tomar la primera.
En definitiva, podemos crear una función que opte por estas dos soluciones cuando una de ellas no tenga éxito.
def antiguedad(texto): try: for item in range(len(texto)): if texto[item] == "antigüedad": if re.match('(\d+(\,|\.)?\d+?(\,|\.)?\d+?|\d+)', texto[item + 1]): antigu = texto[item+1] fechaclean = re.sub('\,|\.|\-|\/', '', antigu) return datetime.strptime(fechaclean, '%d%m%Y').date() except: fechas = [word for word in texto if re.match('\d{1,2}(\/|\.|\-)\d{1,2}(\/|\.|\-)\d{1,4}', word)] fechaclean = re.sub('\,|\.|\-|\/', '', fechas[0]) return datetime.strptime(fechaclean, '%d%m%Y').date() |
Una vez que obtengamos el token en formato fecha, se procederá igualmente a limpiarlo y pasarlo por la librería «datetime», para que sea un dato tratable, esto es, para que podamos sumar y restar días entre las fechas y obtener los datos necesarios para el cálculo de la indemnización.
3. Salario
Para obtener el salario que servirá de base para el cálculo de la indemnización, acudiremos a aquél token que precede a la palabra «euros» o «€» y que tenga formato de número. Una vez obtenido, lo limpiaremos y adecuaremos a la librería «math», dado que el formato de «math» no admite la «,» sino el «.» para distinguir los decimales. Así mismo, eliminaremos el «.» para distinguir las centenas.
def salario(texto): for item in range(len(texto)): if '€' in texto[item] or 'euros' in texto[item]: if re.match('(\d+(\,|\.)?\d+?(\,|\.)?\d+?|\d+)', texto[item-1]): return float(re.sub(',', '.', texto[item-1])) |
4. Cálculo de la Indemnización
Como se ha venido señalando, al crear distintas funciones, estas pueden usarse unas dentro de otras, para el cálculo de la indemnización deberemos tener cada uno de los datos necesarios, y para ello llamaremos a la función dentro de la propia función de indemnización, de tal manera que el único parámetro a facilitar será el texto de la demanda.
Por tanto, el uso de funciones nos facilitará la tarea de crear nuevos algoritmos empleando «piezas» de código que hacen un función concreta que nos puede ser de utilidad para otras finalidades.
VI. Vista al futuro
El ejemplo mostrado ut supra no deja de ser un caso concreto, un programa dedicado, no generalista y que se limita a extraer los datos según la estructura de los modelos de demanda de despido de tres despachos distintos (los que mayor porcentaje de litigiosidad presentan). El código reconoce, según el nombre del abogado, qué patrón seguir para extraer los datos. Los futuros Sistemas de Gestión Procesal deberían partir de un sistema de Inteligencia Artificial al que habrá que entrenar y que nos podrá brindar muchos más datos, pero sobre todo nueva información.
A este respecto, el análisis del texto de la demanda y de la contestación, permitirían que si en la demanda se habla de un hecho en concreto, la IA del Sistema de Gestión Procesal, vinculara ese hecho concreto de la demanda con la parte correlativa de la contestación y con el minuto y segundo concreto de las declaraciones de partes, testigos y peritos sobre tal hecho en concreto, tanto con el vídeo como con su transcripción, y por último la referencia que a tal hecho se hagan en las respectivas conclusiones. De tal manera que un hecho concreto controvertido de lugar a un árbol de recursos a los que el Juzgador acudirá para su examen y valoración. En definitiva, limitar la actividad del Juzgador, para que no haya de «escudriñar» o «bucear» en el Expediente, sino que la IA le haya ordenado la información y se la muestre. En segundo lugar, todas las declaraciones habrán de ser transcritas por la IA con la minutación y la opción de cliquear en la frase concreta para que aparezca el video en el momento oportuno de su pronunciación. En tercer lugar, las referencias que se hagan a las leyes o jurisprudencia, el reconocimiento de texto por la IA, debería integrar enlace automático a la Base de Datos del CENDOJ, para su examen. Y en cuarto lugar, la IA habrá de ofrecer una relación de casos semejantes al examinado, organizados en estimados y desestimados, a través del procesamiento de lenguaje natural, con bibliotecas como las anteriormente expuestas.
En definitiva, el Expediente ha de facilitar la labor del Juzgador, que nunca podrá tener un Expediente físico, por lo que el Expediente Virtual habrá de ofrecer todas las facilidades posibles y potenciar aquellas herramientas que facilitan y favorecen la productividad. Y todo ello, siempre y cuando los escritos tengan un texto tratable.
VII. Otros casos de uso
El caso de uso mostrado toma la estructura de distintos modelos de demanda para extraer datos de interés y hacer los cálculos de indemnización. Para poder extender un programa de este tipo sería preciso un motor de IA con identificación de POS (Part of Speech) al que entrenar para poder llevar a cabo un reconocimiento general.
Un código como el expuesto no es generalista, sin embargo, un algoritmo semejante podría obtener una gran cantidad de datos si las demandas y contestaciones respondieran, al menos en algunas de sus partes, a estructuras estereotipadas. La estereotipación de algunas partes de los escritos procesales permitiría que los algoritmos para extraer la información fueran más sencillos y transparentes. Ello no obstante, en el ámbito de la justicia, existen determinados documentos que sí están estereotipados y con los que trabajamos los Juzgadores diariamente. Uno de esos documentos serían los atestados de los distintos cuerpos de las FFCCSS. Un algoritmo que extrajera de los atestados los hechos denunciados, los nombres de las partes (denunciantes, denunciados), así como los delitos denunciados, permitirían crear un documento ad hoc de borrador de Sentencia de delitos leves. En dicho borrador, el encabezado tendría a las partes, los hechos probados partirían de los denunciados, para poder modificar los mismos, cambiarlos o mantenerlo en función de la prueba que se practique, y en los fundamentos contener la expresión de una jurisprudencia genérica sobre el tipo de delito leve denunciado y su articulado.
Así mismo, los Expedientes del INSS en materia de incapacidades, también responden a estructuras predefinidas, por lo que un algoritmo podría extraer la información sobre el cuadro clínico residual, las limitaciones orgánicas y funcionales, las conclusiones el Informe Médico de síntesis, las patologías previas y las actuales, la base reguladora, los descuentos etc… Esto es, toda aquella información que se hace constar en los Hechos Probados y que sin embargo no supone una labor jurídica, sino una transcripción de datos incontrovertidos.
En definitiva, un algoritmo simple que extraiga los datos de aquellos documentos estereotipados no precisaría de un motor de IA complejo, más allá de un análisis de la estructura de cada documento.
VIII. Siguiente paso
Como se ha expuesto, extraer los datos más importantes de los escritos de las partes y reunirlos en un solo documento sólo serviría para evitar el trabajo de cotejo y búsqueda de esos datos a lo largo del expediente. Sin embargo, la extracción de estos datos, o al menos de algunos de ellos tendría más interés se uniera a la creación de Smart forms de Sentencias.
El 16 de Junio de 2020, el Pleno del Consejo General del Poder Judicial aprobó el Plan de Choque para la reactivación tras el Estado de Alarma. Entre los principios inspiradores de las medidas organizativas y procesales señalan la «automatización y estereotipación de resoluciones habituales». Así mismo, como medidas gubernativas y organizativas a impulsar por el Consejo, se señala la medida «6.35: Automatización y estereotipación de resoluciones habituales».
Los Sistemas de Gestión Procesal y la modernización de la Justicia ha tenido siempre un objetivo claro, la Administración. Sin embargo, la modernización de la propia labor judicial e integrar los avances en cuestiones como la expuesta es una necesidad para la propia evolución de la justicia y para la agilización de la misma.
IX. Código fuente
Disponible en:
https://github.com/xvi82/buscador